The book is divided into three main sections: the first section provides an introduction to data engineering and explains the fundamental concepts and principles behind it. The second section covers the various technologies and tools that are used in data engineering, including Hadoop, Spark, Kafka, and many others. Each technology is described in detail, with practical examples and use cases that demonstrate how it can be used in real-world scenarios.
The final section of the book focuses on best practices for building and managing data pipelines. This section covers topics such as data governance, data quality, and data security, and provides practical tips for ensuring that data pipelines are reliable, scalable, and secure.
One of the key strengths of The Big Book of Data Engineering is its focus on practical examples and real-world scenarios. The authors have clearly drawn on their extensive experience in the field to provide readers with insights and best practices that are immediately applicable in a variety of contexts.
In addition to its practical focus, the book also provides a thorough theoretical foundation for data engineering. The authors explain key concepts such as distributed computing, data warehousing, and stream processing in clear and accessible language, making the book an excellent resource for both beginners and experienced data engineers.
Overall, The Big Book of Data Engineering is a valuable resource for anyone working in the field of data engineering. Whether you're just starting out in the field or are an experienced data engineer looking to deepen your knowledge, this book provides a comprehensive and practical guide to the technologies and tools that are used in modern data engineering.
 Waymo Data Scientist interview
04/04/2023
Waymo Data Scientist interview
04/04/2023
 What is intelligent electronic device?
03/04/2023
What is intelligent electronic device?
03/04/2023
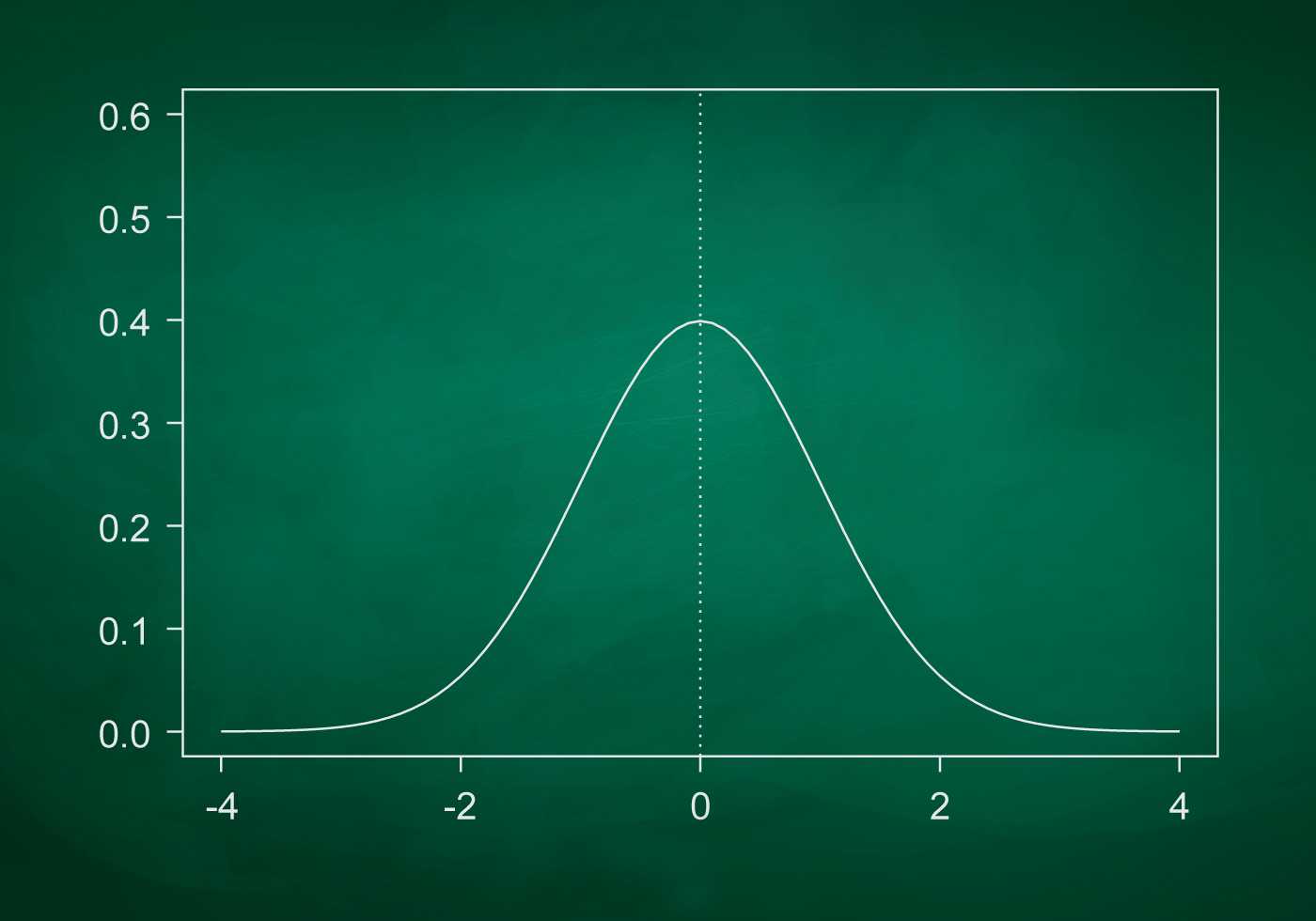 What is standard deviation definition
10/11/2022
What is standard deviation definition
10/11/2022
 What is Power BI and how to use it
10/11/2022
What is Power BI and how to use it
10/11/2022

