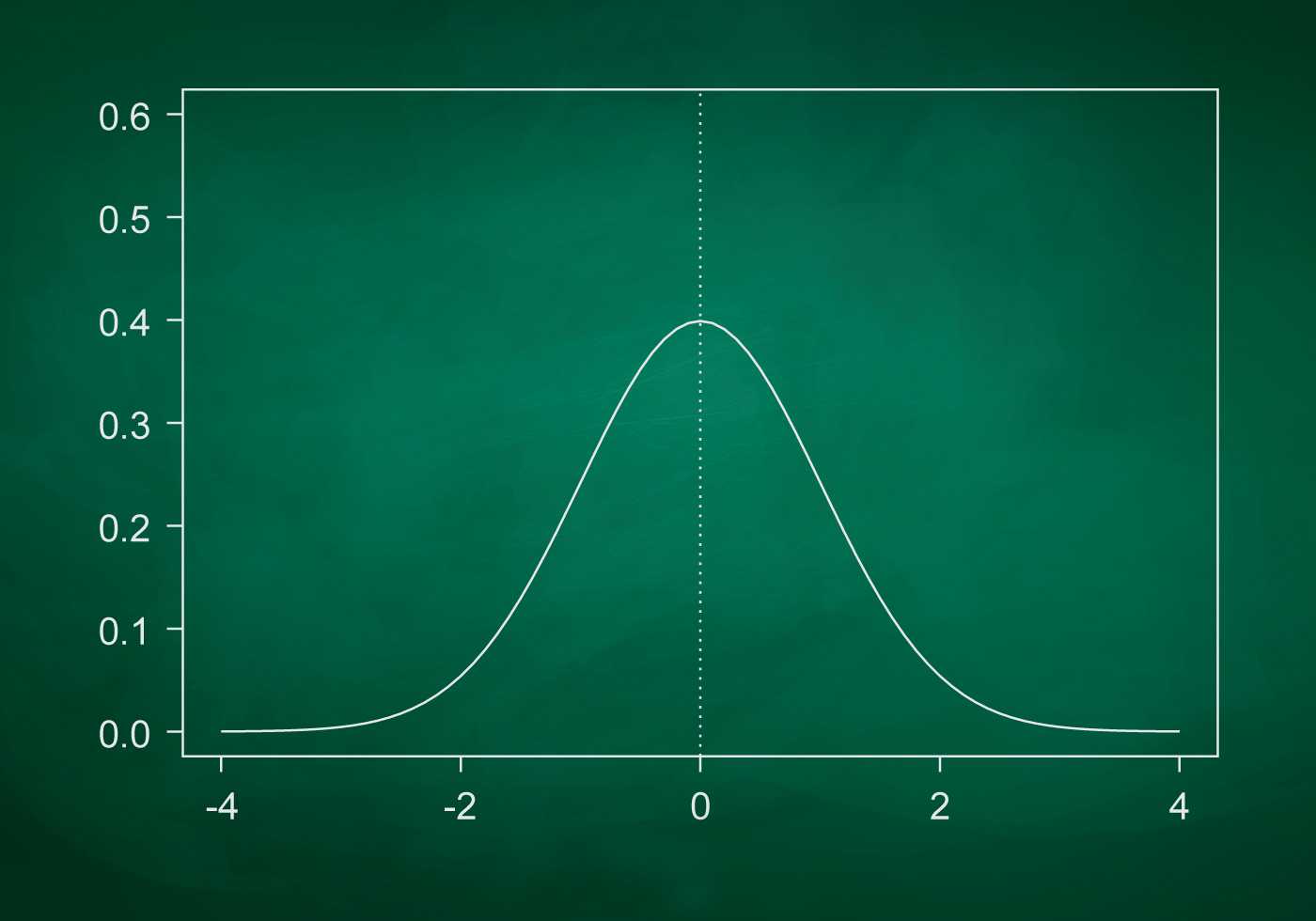
The standard deviation is, in simple terms, a measure of how scattered the data set is.
By calculating it, you can find out whether the numbers are close to or far from the mean. If the data points are far from the mean value, then there is a large deviation in the data set; thus, the greater the scatter in the data, the higher the standard deviation.
The standard deviation is denoted by the letter σ (Greek sigma).
Standard deviation is used
The standard deviation (σ, s) is a measure of the scatter in a set of numerical data. In simple terms, how far from the arithmetic mean (Mean) the data points are. It can also be called a measure of central tendency: the smaller the standard deviation, the more "clustered" the data are around the centre (the mean).
The standard deviation can be expressed by the formula STD=√ (∑ (x-x)2)/n], which sounds like the root of the sum of the differences between the sample items and the mean, divided by the number of items in the sample."
Should read: "Standard deviation can be expressed as STD=√ (∑ (x-x)2)/n], which sounds like the root of the sum of the squares of the differences between the sample items and the mean divided by the number of items in the sample.
The standard deviation (SD), measures the amount of variability, or dispersion, of individual data values, to the mean, while the standard error of the mean (SEM) measures how far a sample mean (mean) of the data is likely to be from the true population mean.
In probability theory and statistics, the standard deviation is the most common measure of the dispersion of values of a random variable relative to its mathematical expectation (analogous to the arithmetic mean with an infinite number of outcomes). It usually refers to the square root of a random variable's variance, but sometimes it may refer to some variant of that value. In the literature, it is usually denoted by the Greek letter. (sigma).
The difference between standard deviation and variance can be clearly defined for the following reasons: Dispersion is a numerical value that describes the deviation of observations from the arithmetic mean. The standard deviation is a measure of the dispersion of observations in a set of data relative to their mean. The variance is nothing more than the mean of the squares of the deviations. Standard deviation, on the other hand, is the standard deviation.
The mean sampling error shows how far the sample population parameter deviates, on average, from the corresponding parameter of the general population.
If we calculate the average of the errors of all possible samples of a certain kind of a given volume (n) extracted from the same general population, we obtain their generalizing characteristic - the average sampling error ().
The oscillation coefficient shows the extent of variation relative to the mean, which can also be used to compare different data sets. Thus, in statistical analysis, there is a system of indicators that reflects the dispersion or homogeneity of data. Below is a video on how to calculate coefficient of variation, variance, standard deviation and other measures of variation in Excel.
The marginal error of sampling is denoted by the Greek letter (delta). It is equal to the product of the sampling error by the corresponding coefficient of confidence. So for the first confidence interval, the coefficient of confidence is for the second, and for the third. Replacing the corresponding formulas for resampling, we obtain:
 Waymo Data Scientist interview
04/04/2023
Waymo Data Scientist interview
04/04/2023
 What is intelligent electronic device?
03/04/2023
What is intelligent electronic device?
03/04/2023
 What is standard deviation definition
10/11/2022
What is standard deviation definition
10/11/2022
 What is Power BI and how to use it
10/11/2022
What is Power BI and how to use it
10/11/2022
 What is ITIL 4 Foundation
13/04/2022
What is ITIL 4 Foundation
13/04/2022
 Best laptop for hacking
10/04/2022
Best laptop for hacking
10/04/2022
 Best laptops for podcasting 2022
10/04/2022
Best laptops for podcasting 2022
10/04/2022


